Methods


QML process flow


Data set

We use the popular open-source Chest X-ray1 Dataset1 that contains 108,948 frontal view X-ray images of resolution 1024x1024 labeled with 14 diseases. Eight of the disease classes are used for training.
1 Xiaosong Wang et al. “Chestx-ray8: Hospital-scale chest x-ray database …”. IEEE conf. on computer vision and pattern recognition (2017).https://nihcc.app.box.com/v/ChestXray-NIHCC
Methods
Quantum annealing uses a physical system of qubits to simulate an instance of a quadratic binary problem (QUBO). After the problem is mapped to the architecture of the annealer, the physical system is given some time to settle (anneal) to its final state that often represent a good solution to the problem. This process can be significantly faster than a classical algorithm for a QUBO problem.
Currently available quantum annealers still have a limited size and qubit connectivity, hence only small problems can fit into them. They are also noisy and error prone. Therefore, we start with a classical pre-processing to reduce the problem size.
In order to embed the images on the D-Wave Advantage 4.1., we need to reduce the size of each sample to approximately 160 bits. A state-of-the-art unsupervised deep feature extractor based on the Solo Learn2 library and BYOL3 method is used to reduce the number of features to 80. Each feature is then quantized as two bits, compressing each image data down to 160 bits.
2 See https://github.com/vturrisi/solo-learn
3 Jean-Bastien Grill et al. “Bootstrap your own latent...”. Advances in Neural Information Processing Systems 33 (2020).
We implemented a state-of-the-art quantum restricted Boltzmann machine (QRBM) is a generative machine learning model. After training, this model can reconstruct not just the labels (image classes), but also some missing features. The model is used to classify medical images into eight classes (eight disease in the selected dataset).
The performance of image classification (or any diagnosis test) is a trade-off between sensitivity or true positive rate (TPR)4 and specificity or false positive rate (FPR)5. For each value of FPR we calculate and plot the maximum TPR the classifier achieves. The larger the area under this curve (AUC), the better the classifier is performing, which varies between 0.5 (random classifier) and 1.0 (perfect classifier).
4 True positive rate (TPR) or sensitivity of the classifier is the proportion of images correctly classified/diagnosed as having a disease.
5 False positive rate (FPR) is the proportion of images incorrectly classified/diagnosed as having a disease. It is related to the specificity (TNR) by TNR = 1 – FPR.
Results
Neither a machine nor a human can achieve 100% accuracy on medical image classification because some images do not have sufficient information for diagnosis. Figure 1a shows the mean AUC score for classification of different diseases using our QRBM model on D-Wave annealer. It is evident that the model can learn how to classify the images, while still having a long way to perfection. Figure 1b compares the training results of QRBM on D-Wave with classical training methods. The training is done in batches and each batch stopped after 10 epochs. The classical models were also stopped at epoch 10. The main sources of error for QRBM are: (a) compression of images to fit quantum device, (c) regularization to ensure that the weights of the model do not exceed the range allowed on the D-Wave device, and (d) fundamental limitations of the current generation D-Wave machines such as qubit count, connectivity and noise. With future scaling of D-Wave annealer technology, it is foreseeable that quantum annealing approach can potentially outperform classical sampling on some difficult tasks for which our classical compute power is not sufficient.
Figure 1: Mean AUC for the final models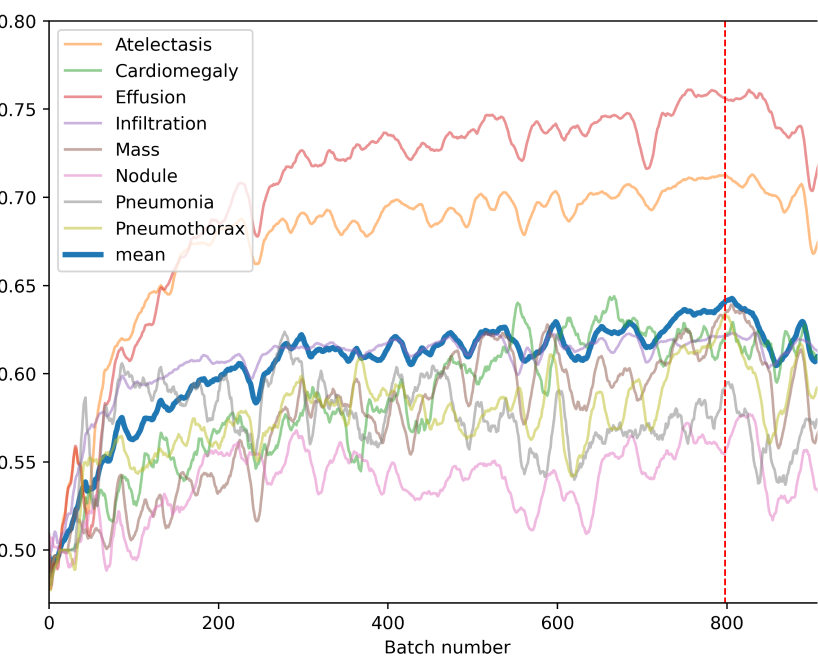
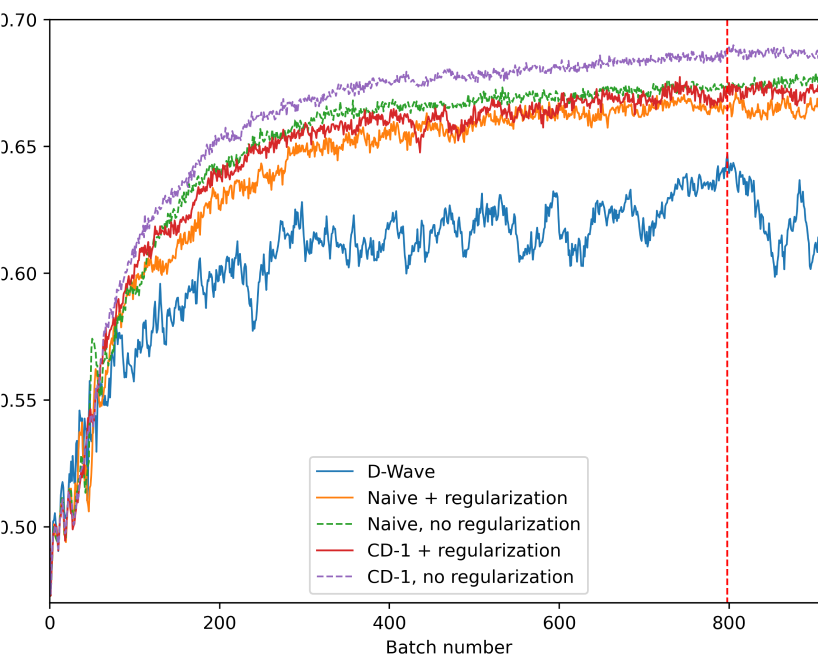
Conclusions
Our implementation of QRBM on a D-Wave annealer and successful demonstration of its learning capability is a big step towards development of quantum machine learning technology for future AI. D-Wave annealers have the promise of being useful samplers for probability discussions that are difficult to handle classically. While today’s quantum annealer has many limitations as an emerging technology, the potential of huge speedup versus classical sampling methods can open doors to the problems that are not computable today. A combination of a D-Wave annealer and classical methods can deliver the best results – an approach we have started to explore in this work.